
"בפעם הראשונה, אנחנו יכולים לענות על השאלה 'מה אם?' בהקשר של מהלכי כדורגל".
אם נבקש מאדם ממוצע לתאר היכן כיום מוטמעת בינה מלאכותית, כנראה שנקבל את אחת התשובות הבאות:
- גוגל
- פייסבוק
- סנאפצ'אט
- רכבים אוטונומיים
- שמעתי שיש דבר כזה רשתות נוירונים
- למידה חישובית וביג דאטה
- שמעתי על זה משהו
- אין לי מושג
אז קודם כל הבהרה; בינה מלאכותית, גם אם בסיסית, כבר איתנו לא מעט זמן. לפני שנתחיל לצלול פנימה, הנה מספר דוגמאות. הדוגמא הראשונה היא כמובן סירי. כבר לא מעט שנים שהמון אנשים מדברים עם סירי בחופשיות והיכולות שלה מתרחבות ומשתפרות. למעשה, כיום ניתן כמעט לשוחח עם סירי שיחה חופשית. סירי היא תוכנה מבוססת בינה מלאכותית. אחת התכונות המרכזיות של בינה מלאכותית היא שהיא לומדת – כלומר משתפרת ככל שהיא צוברת נסיון. דוגמאות נוספות: חיפוש בגוגל, תרגום גוגל, מערכות המלצה לקניות (מכירים את "Recommended For You" באמזון/איביי?), זיהוי פנים בתמונות, תיוג אוטומטי בתמונות בפייסבוק, זיהוי עצמים אוטומטי בתמונות, השלמת חיפוש/כתובת אינטרנט בצורה אוטומטית. למעשה, אם אתם חשים ש"עוקבים" אחרי כל דבר שאתם עושים, זה כנראה מכיוון שבאמת עוקבים אחרי כל דבר שאתם עושים, ויש לכך סיבה. התמונות המצורפות כאן הן דוגמאות לטכנולוגית זיהוי פנים ולטכנולוגית זיהוי אובייקטים.

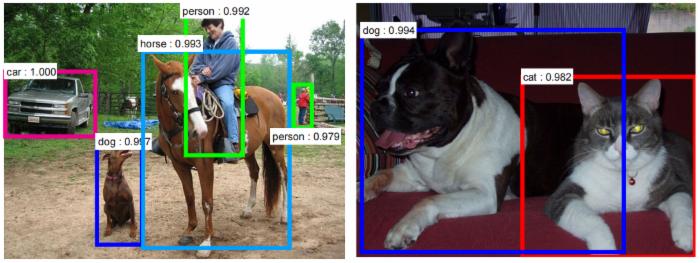
בתמונה הראשונה מדובר באלגוריתמים די ישנים. כיום, לאור פריצות דרך מחקריות בנושא למידה חישובית עמוקה, אפשר כבר להגיע לביצועים מרשימים הרבה יותר, כמו שניתן לראות בתמונה השניה.

בתמונה 3 כבר ניתן לראות זיהוי תבניות תנועה של אדם. תבנית תנועה היא ייחודית לכל אדם, לכן זיהוי ושמירה של תבנית זו יכולים לשמש למעשה כאמצעי זיהוי בכל מקום. המשותף לכל האנשים אותם שאלתי על בינה מלאכותית, הוא שאף אחד מהם לא העריך נכונה את רמת החדירה של בינה מלאכותית לחיינו. אף אחד מהם גם לא חשב שחזית המחקר בבינה מלאכותית כיום, היא בתחום קרוב לכולנו – ספורט.
הסטוריה
למעשה, רעיונות לתכנון מכונות שיכולות לחקות "הגיון" ולפעול בצורה נבונה אינם חדשים כלל. בערך ב-1670, לייבניץ, מאבות החשבון הדיפרנציאלי, העלה את הרעיון לבנות מכונה שמבצעת פעולות על רעיונות ולא על מספרים. כלומר המכונה מקבלת כקלט פקודה מילולית (למשל "הרם את הכוס"), מזהה את מצב העולם ("הכוס מונחת על השולחן") ומבצעת את הפעולה הנדרשת. כמובן שבתקופתו הרעיון נזנח ונשאר בגדר מדע בדיוני, עד 1956. בזמן זה כבר היו קיימים מחשבים וצוות הכולל חוקרים מהמכון הטכנולוגי של מסצ'וסטס (MIT), אוניברסיטת קרנגי מלון (CMU) ו-IBM. החוקרים יצרו מכונות שדיברו אנגלית, שיחקו שח-מט והוכיחו משפטים במתמטיקה. באמצע שנות השישים התחום פרח ומשרד ההגנה האמריקאי השקיע הון בקידום המחקר בתחום הבינה המלאכותית, שבתקופה זו התמקד בפיתוח אלגוריתמים שפותרים בעיות בצורה נבונה. האמונה הרווחת היתה שתוך 20 שנה מכונות יוכלו לבצע כל מטלה שאדם יכול לבצע. ובכן, לא כך קרה.
השנים עברו, הקשיים גברו ולא הוערכו נכונה. ב-1974, הקונגרס האמריקאי הפסיק את מימון המחקר בנושאי בינה מלאכותית והתחום כולו שקע אל תוך מה שקרוי עד היום "החורף של הבינה המלאכותית". בתחילת שנות ה-80, חווה התחום פריחה קצרה ועוד לפני תום העשור שקע שוב.
ואז בא האינטרנט
הרבה מן הבעיות בתחום הבינה נבעו מהרעיון הכללי מאחוריה. הגישה המסורתית לתכנון, כללה תכנות של מחשב להגיב למספר תרחישים אפשריים. עבור כל תרחיש שהמחשב מזהה – קיימת תגובה מוכנה שתוכנתה בו מראש. הבעיה היתה שילוב המחשב בסביבה אנושית, בה לא ניתן לדעת מראש מהם כל התרחישים האפשריים בהם הוא עלול להיתקל. הגישה פשוט לא עבדה. עם התפתחות תחום הלמידה החישובית, שבראשיתו היה תחום שונה מבינה והיום תחומים אלו מאוחדים, החלו להופיע רעיונות שונים. במקום לנסות לתכנת את המחשב בצורה מתוחכמת, פשוט נלמד את המחשב לזהות סיטואציות שונות ותגובות אפשריות לסיטואציות אלו. עבור כל תגובה אפשרית, נזין במחשב ציון, כך שהמחשב יכול כעת לדעת עבור סיטואציה ספציפית מהי תגובה טובה יותר ומהי תגובה טובה פחות. רעיון זה נקרא למידה מפוקחת (Supervised Machine Learning) והוא קיים שנים רבות. עם זאת, עד תחילת שנות האלפיים הלמידה החישובית דשדשה עקב שתי בעיות מרכזיות.
הבעיה הראשונה – בכדי ללמד מחשב "מקרים ותגובות" בצורה מספיק טובה, כך שהוא יוכל לפעול בסביבה כללית עם אי ודאות, נדרשת כמות עצומה של דוגמאות מתויגות בתהליך הלימוד. דוגמא טובה לכך היא זיהוי פנים. בכדי שמחשב יוכל לקבל כקלט תמונה שהוא לא ראה מעולם ולסמן על גביה היכן נמצאים פנים, יש להראות לו עשרות אלפי תמונות מתויגות בתהליך לימוד. כלומר, יש להראות לו תמונות שבהן מישהו כבר סימן היכן יש פנים וכך הוא לומד. אז אמנם לא צריך "לתכנת" אותו להבין איך נראים פנים, ולכן נחסך הקושי המשמעותי שכרוך בלתאר מתמטית מהם פנים בצורה כללית, אך כעת צריך להשיג עשרות/מאות אלפי דוגמאות מתויגות.
הבעיה השניה – מכיוון שתהליך האימון דורש כמות עצומה של דוגמאות, משאבי המחשוב הנדרשים עבור ביצוע האימון הם אדירים. בתום האימון ניתן להריץ את התוכנה על כל מחשב, אך מהלך האימון דורש אמצעי מחשוב כבירים.
הבעיה השניה נפתרה פשוט על ידי התקדמות טכנולוגית בתחום המעבדים. הבעיה הראשונה נפתרה על ידי האינטרנט. באמצעות האינטרנט ניתן להשיג היום כמות תמונות גדולה ככל שנרצה. למעוניינים להרחיב ידיעתם בנושא למידה עמוקה, שהיא למעשה הטכניקה הנפוצה ביותר היום בתחום, אני מצרף לינק להרצאת טד נחמדה בנושא.
ספורט
אז אחרי העיקוף הקצר שעשינו בכדי להכיר קצת את התחום, אפשר להגיע לנושא שמעניין אותנו – בינה מלאכותית בספורט. באופן מסורתי, כל תחומי הספורט נעזרים בסטטיסטיקה שנאספת במהלך משחקים. עד לאחרונה השימוש בסטטיסטיקה הנאספת היה פרימיטיבי ביותר, אך בעשרים השנים האחרונות חלה התקדמות משמעותית מאוד בתחום. רבות דובר, גם כאן בטורים שלי, על איסוף וניתוח מידע בספורט, אך נראה כי בתקופה הנוכחית מתרחשת פריצת דרך עצומה המשלבת בינה מלאכותית עם ניתוח מידע. המצע עליו החלה המהפכה הוא כמות המידע. מערכות לומדות מכל הסוגים, דורשות כמויות מידע עצומות בכדי להפיק תוצאות משמעותיות. בספורט, באופן מסורתי, כמעט כל המשחקים מצולמים ומוקלטים, לכן ניתן גם בדיעבד ללמוד המון ממשחקים שכבר שוחקו וכך בעצם לבנות מאגר מידע עצום המכיל כמות בלתי נגמרת של משחקים לשימוש בתהליך האימון. חשוב להבין שמאגרי המידע העצומים הללו הם למעשה האוצר היקר של חברות ניתוח המידע.

אם נחזור לרגע לפסקה הראשונה שבה אמרתי שאם אתם מרגישים שעוקבים אחריכם זה כנראה נכון, אז זו הסיבה. לפתח אלגוריתם לומד, שידע לצורך העניין לזהות את מסי בקטע וידאו, זו לא בעיה. לספק לו מספיק סרטונים של מסי לתהליך האימון, כך שיוכל להבדיל בינו לבין שחקנים אחרים, זו כבר בעיה גדולה מאוד. לכן מי שבידיו מאגר סרטונים כזה הוא אדם עשיר מאוד. לכן גם, חברות ענק כמו פייסבוק וגוגל מעודדות אותנו "לשתף" הכל – תמונות, סרטונים, סטטוסים, מה אנחנו אוהבים ומה לא וכו'. כך למעשה הן בונות מאגרי מידע עצומים ומתויגים, ששווים הון ושייכים רק להן מבלי לשלם לנו כלום.
בספורט כבר קיימת כמות עצומה של מידע סטטיסטי שנאסף ותויג לאורך המון שנים, לכן ניתן להשתמש בו כדי ליצור אלגוריתמים לומדים. ב-2015, חברה אמריקאית בשם STATS ("Sports Team Analysis and Tracking Systems") רכשה את חברת פרוזון (PROZONE) והפכה לחברת הספורט דאטה הגדולה בעולם.
למעוניינים: https://www.stats.com/
לפני בערך חמש שנים, STATS התקינה מערך מצלמות מיוחד בכל אולמות הכדורסל ב-NBA ובאצטדיוני כדורגל נבחרים באירופה והחלה באיסוף נתונים. באמצעות שמונה מצלמות, ניתן לעקוב אחרי כל שחקן במהלך כל המשחק ברמת דיוק גבוהה מאוד ובקצב דגימה גבוה במיוחד; המצלמות מצלמות בקצב של 25 תמונות בשניה, משמעותית מהר יותר מ-GPS ומשמעותית מדויק יותר. מטרת איסוף המידע, היא בסופו של דבר לייצר מאגרי מידע מתויגים אשר מכילים תיוגים כגון: מהלכים התקפיים טובים (וכאלה שהובילו לשערים), מהלכים הגנתיים טובים (וכאלה שמנעו שערים, מה שקשה יותר לתייג, הרי איך יודעים שמנענו שער?) וכו'. לאחר מכן ניתן להזין את מאגרי המידע העצומים הללו לאלגוריתם לומד ולהתחיל לייצר מהלכים חדשים עם אותו תיוג. ניתן אפילו לייעל אותם, כך שיתקבלו מהלכים חדשים אשר מעלים את ההסתברות לכיבוש שער, או לחילופין מהלכים הגנתיים או מערכים אשר מפחיתים את ההסתברות לספיגת שער למינימום. נשמע קשה? זה אכן כך, אך אפשרי. התהליך עצמו הוא תהליך אופטימיזציה מורכב מאוד, אך עם זאת פריצות דרך בתחום המחשוב (בעיקר הודות לחברת NVIDIA) ובמחקר בתחום הלמידה העמוקה ורשתות נוירונים מאפשרות לכך לקרות. אם כך – מאניבול OUT, בינה מלאכותית IN.
למה זה קשה ומהם האתגרים?
עם התפתחות תחום האימון בעשורים האחרונים, החל מפילוסופיות המשחק השונות וכלה בהתמקצעות בכל התחומים הקשורים למשחק (תזונה, כושר גופני, שינה, פסיכולוגיה, טקטיקה, לבוש וכו'), הקושי לייצר חדשנות הולך ועולה והסיכוי לחשוב על דברים שעוד לא חשבו עליהם הולך ופוחת. אם כן, בכדי לטייב את הביצועים על הדשא, או על כל מגרש אחר, יש להמציא יש מאין. מצד אחד, תמיד נראה כאילו לא ניתן לייצר כבר שום דבר חדש וראינו הכל. מצד שני, אם מנסים לחשב את מס' האופציות האפשריות לסדר עשרה שחקני שדה במערך ומנסים להתחשב בכל המערכים האפשריים ובכך שקבוצה יכולה להחליף מערכים מספר פעמים במשחק בצורה אקראית או עקב אירוע כלשהו, מגיעים למספר דימיוני של אופציות אפשריות העולה על מספר האטומים ביקום כולו. זו למעשה הסיבה שתמיד ניתן להמציא משהו חדש ושכל פעם שאנו רואים משהו כזה, אנחנו מיד חושבים "איך אף אחד לא עשה את זה קודם?". האמת היא שיש המון אפשרויות, אך קשה מאוד למצוא אחת כזו. בבעיות מסוג זה, שיטות אופטימיזציה מבוססות בינה מלאכותית פורחות. הן יכולות לייצר פתרונות חדשניים ככל שרק נרצה. למרות זאת, עדיין יש מספר אתגרים קשים מאוד כאשר עוברים להשתמש בשיטות אלו.
- האלגוריתם הרי לא "מבין" כדורגל, כיצד מסווגים את ההצעות שלו להצעות יעילות ומוחקים את כל השאר?
- כיצד מספקים מספיק מידע מתויג לאלגוריתם הלומד? הרי מהלך מוצלח מסוים לא חוזר על עצמו יותר ממספר בודד של פעמים, אחרת קבוצות לומדות להתגונן מולו ואז הוא מפסיק להיות מוצלח. אלגוריתם לומד צריך עשרות אלפי דוגמאות (לפחות!) לכל מהלך. כיום אין פתרון לשאלה זו.
דוגמה
ב-STATS מנסים כבר לא מעט שנים לענות על השאלה הבאה: "בהינתן מהלך התקפי נתון, מהו המהלך ההגנתי האופטימלי?"
לאחרונה, שיתוף פעולה בין STATS לחברת Disney ואוניברסיטאת Caltech יצר תשובה חדשה. הפיתוח נקרא Data-Driven Ghosting using Deep Imitation Learning והוא מבוסס על רעיון שהוצג ב-2013 על ידי הטורונטו רפטורס מה-NBA. בטורונטו יצרו (בעמל רב יש לציין) מערכת הנקראת Ghost. במערכת זו הוקלטו מהלכי התקפה רגילים, בעוד צוות האימון מסמן וירטואלית איפה לדעתם המגינים צריכים לעמוד בכל רגע על מנת להגן בצורה אופטימלית. לאחר שסיימו לבנות מאגר הכולל את כל מהלכי ההתקפה האפשריים לדעתם, היה בידם מאגר מידע קטן יחסית הכולל את ההתגוננות האופטימלית, לדעת צוות האימון, כנגד כל אחד מן המהלכים. כעת, ניתן היה לשחק משחקים רגילים תוך כדי העונה ובניתוח של המשחק לאחר סופו, ניתן היה להשוות את ההתנהגות של השחקנים בפועל במשחק אל מול ההתנהגות האופטימלית בכל מצב ולראות האם ישנם הבדלים ואם אכן ישנם, לתקנם. ב-Disney וCaltech לקחו את הרעיון הזה אל הקצה. באמצעות אלגוריתם לומד, בנו מערכת Ghosts מתוחכמת מאין כמוה עבור כדורגל. בניגוד לטורונטו, המערכת של Disney לומדת את אסטרטגיית ההגנה האופטימלית מול כל מהלך התקפי, על יד צפייה באלפי מהלכי כדורגל ולא בצורה ידנית. כך נבנה לו מאגר של מהלכי הגנה אופטימליים. ה-Ghosts של Disney למדו לבדם מתי כדאי ללחוץ כקבוצה, מתי לשמור אישית, כיצד לסגור קווי מסירה וכו'. הכל בצורה אוטומטית ולא מפוקחת. כעת גם קבוצות כדורגל יכולות לנתח מהלכים לאחר משחקים ולראות האם אכן שחקניה מתנהגים בצורה אופטימלית באמצעות השוואתם ל-Ghosts. אם זה לא מספיק, לאחרונה התאפשר אפילו להתאים את מודל הקבוצה מולה מתגוננים לקבוצות ספציפיות. כך למשל, ניתן להתגונן ספציפית מול הסגנון של ריאל מדריד או כל קבוצה אחרת. כיום, המידע המוצג מהתוכנה מוצג בזמן אמת על גבי המשחק האמיתי. צוות האנליסטים יושב במשרד ורואה את המשחק בזמן אמת על המסך, כאשר בנוסף לשתי הקבוצות המשחקות על הדשא הוא צופה גם במיקומי ה-Ghosts על הדשא ויכול ליצור קשר עם צוות האימון תוך כדי המשחק ולעדכן אם מתגלות בעיות ספציפיות, כגון שחקן שלא סוגר נכון וכו'. אם לשפוט לפי הטרנדים הנוכחיים וקצב המעבר של טכנולוגיות מעולם המחקר לעולם העסקי, כנראה שבחמש השנים הקרובות נראה מהפכה בתחום השימוש במידע ובבינה מלאכותית בכל ענפי הספורט עקב ההתפתחויות הגדולות במחקר בתחום ובענף כריית המידע.
לסיום, חשוב לציין שבינה מלאכותית בעולם הספורט נמצאת בחזית המחקר מבחינת אתגרים ושווי כלכלי. יישומים נוספים לבינה מלאכותית כיום בספורט כוללים פיתוח תוכניות אימונים מותאמות אישית לספורטאים, תזונה ותרופות מותאמות אישית בהתאם למדדים בזמן אמת של ספורטאים, זיהוי תבניות במשחקים, חלוקה של סטטיסטיקות לקבוצות השפעה שונות (אילו סטטיסטיקות משפיעות יותר ואילו פחות על התוצאה), ניתוח מהלכים בזמן אמת עבור שידורי טלויזיה, הערכת מדדים פיזיים של שחקנים ללא שימוש בחיישנים כלשהם ועוד.
סרטון המסביר על המחקר של Disney וCaltech:
קישור לאתר הכנס המכיל עוד הרצאות מצולמות ואת כל המאמרים שהשתתפו השנה: http://www.sloansportsconference.com/
השתתפו בהכנת הטור: רוני כהן פבון, משה אבשלום, מאור אלבז, ריו אילינסקי, טמיר זוארץ, רוני אלפרן, רועי זגה, ברק קורן, יוחאי שטנצלר ורז יניב.
